
Системное администрирование — это не просто “починить принтер” и не магия из подвала с мигающими лампочками. Это инженерная дисциплина, которая держит в рабочем состоянии весь машинный цех компании: серверы, сети, рабочие станции, учётные записи, резервное копирование, обновления, безопасность, мониторинг и восстановление после аварий.
Если совсем по-деловому, системный администратор отвечает за то, чтобы ИТ-среда была:
- доступной — сервисы открываются, рабочие места запускаются, почта ходит;
- предсказуемой — сбои не превращаются в сюрпризы;
- безопасной — доступы, патчи, сегментация, резервные копии;
- управляемой — инфраструктуру можно поддерживать, масштабировать и документировать.
В целом это главный механик огромного парового завода: он следит за давлением в трубах, смазкой шестерён, исправностью клапанов и тем, чтобы котёл не рванул в самый неподходящий момент.

Из чего состоит работа системного администратора
Круг обязанностей зависит от размера компании, но в основе почти всегда лежат одни и те же направления.
Поддержка серверов и сервисов
Сисадмин следит за тем, чтобы работали:
- файловые серверы;
- домен и каталог пользователей;
- почта;
- базы данных;
- виртуализация;
- внутренние веб-сервисы;
- облачные интеграции.
На практике это означает обновления, перезагрузки, проверку журналов, контроль ресурсов и быстрое устранение отказов.
Примеры типичных команд в Linux:
# Посмотреть нагрузку и процессы
top
# Проверить место на дисках
df -h
# Посмотреть состояние службы
systemctl status nginx
# Изучить последние ошибки
journalctl -u nginx --since "1 hour ago"
# Проверить сетевые порты
ss -tulpnПримеры типичных действий в Windows Server:
- проверка состояния служб через
services.msc; - анализ событий в Event Viewer;
- работа с PowerShell;
- контроль ролей AD DS, DNS, DHCP;
- проверка обновлений и перезапусков.
Get-Service | Where-Object {$_.Status -ne 'Running'}
Get-EventLog -LogName System -Newest 50
Get-ComputerInfo | Select-Object CsName, WindowsVersion, OsHardwareAbstractionLayerПользователи и доступы
Очень часто системное администрирование сводят к “создай доступ, удали доступ, сбрось пароль”. Но это только верхний слой котла.
Сисадмин управляет:
- учётными записями;
- группами;
- ролями;
- правами на файлы и каталоги;
- доступом к VPN;
- подключением к корпоративным ресурсам;
- политиками входа и ограничениям.
В доменной среде это может выглядеть так:
New-ADUser -Name "Ivan Petrov" -SamAccountName ipetrov -Enabled $true
Add-ADGroupMember -Identity "HR" -Members ipetrov
Disable-ADAccount -Identity ipetrovХорошая практика — не давать права “на всякий случай”. Чем больше случайных ручек, тем выше шанс, что паровая машина начнёт свистеть не в ту сторону.
Сеть и связность
Если сервер — это котёл, то сеть — это трубопроводы. Без них всё железо превращается в дорогую статую.
Сисадмин контролирует:
- маршрутизацию;
- DNS;
- DHCP;
- VLAN;
- VPN;
- firewall;
- Wi-Fi;
- качество канала связи;
- доступность внешних и внутренних сервисов.
Частые команды для диагностики:
ping 8.8.8.8
traceroute example.com
dig company.local
ip a
ip rДля Windows:
ipconfig /all
Test-NetConnection google.com -Port 443
Resolve-DnsName company.local
route printРезервное копирование и восстановление
Бэкап — это не роскошь, а страховочный клапан. Без него любая авария может стать катастрофой.
Задача системного администратора:
- настроить регулярные копии;
- хранить их по правилу 3-2-1;
- проверять успешность заданий;
- тестировать восстановление;
- документировать RPO и RTO.
Правило 3-2-1:
- 3 копии данных;
- 2 разных типа носителей;
- 1 копия вне основной площадки.
Типичный цикл:
- База данных или файловый сервер попадает в расписание.
- Копия уходит в локальное хранилище.
- Вторая копия реплицируется в отдельное место.
- Админ проверяет лог задачи.
- Раз в месяц делается тестовое восстановление.
Пример проверки архива в Linux:
tar -tzf backup-2026-06-22.tar.gz | headПример теста в PowerShell:
Get-WBJob
Get-WBBackupSetОбновления и патчи
Патчи — это смазка для шестерён. Если их не наносить, механизм начнёт заедать и нагреваться.
Сисадмин отвечает за:
- обновление ОС;
- обновление прикладного ПО;
- исправление уязвимостей;
- контроль совместимости;
- плановые окна обслуживания.
Нормальная практика:
- сначала тестовая группа;
- потом пилот;
- затем промышленная среда;
- обязательно с откатом.
Пример для Linux:
apt update
apt list --upgradable
apt upgradeПример для RHEL-подобных систем:
dnf check-update
dnf upgradeМониторинг и реакция на инциденты
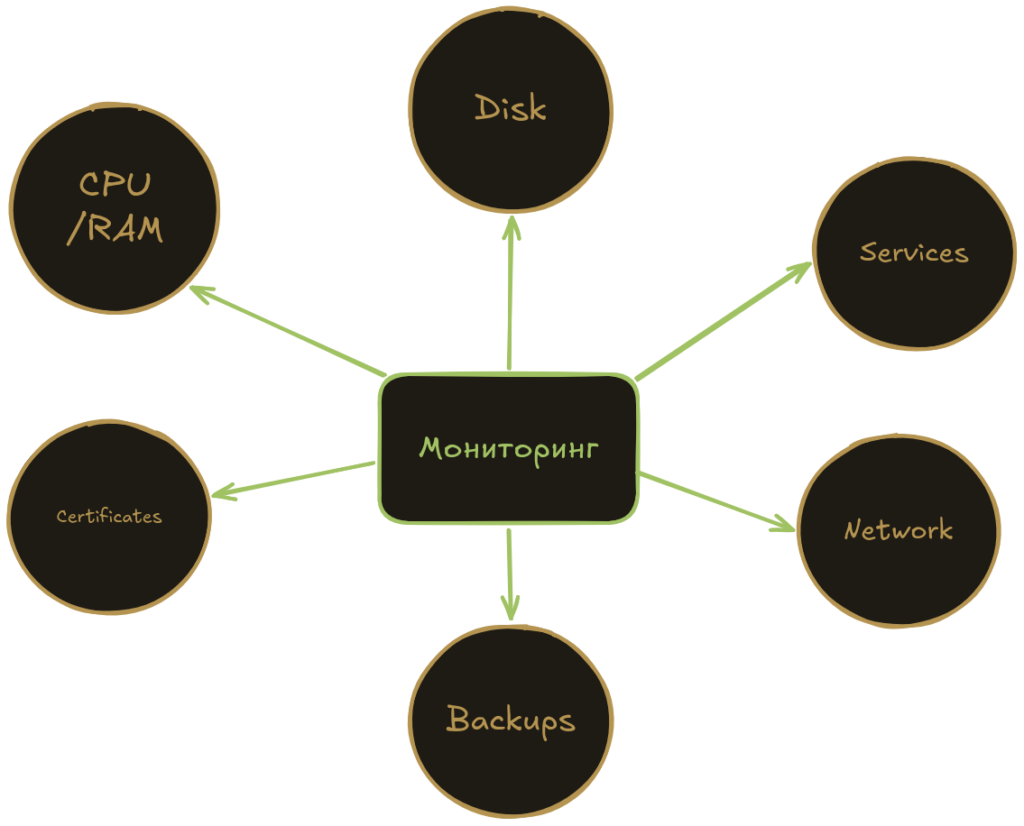
Если система молчит, это не всегда хорошо. Иногда она просто уже падает без шума.
Мониторинг нужен для:
- загрузки CPU и RAM;
- заполнения дисков;
- состояния сервисов;
- ошибок приложений;
- задержек сети;
- состояния сертификатов;
- доступности сайтов и API.
Безопасность
Безопасность — это не отдельная полка в шкафу, а слой, который проходит через всё системное администрирование.
Сисадмин обычно участвует в:
- управлении паролями и MFA;
- ограничении прав;
- обновлении уязвимых компонентов;
- настройке firewall;
- аудите логов;
- контроле внешних носителей;
- базовой антифрод-защите;
- сегментации сети;
- управлении сертификатами.
Полезные привычки:
- не использовать один и тот же пароль для сервисов;
- отделять административные учётки от рабочих;
- выдавать минимально необходимые права;
- вести журнал изменений;
- регулярно просматривать логи входов.
Документация и регламенты
Документация — это чертёж парового двигателя. Без неё любая замена шестерни превращается в археологические раскопки.
Сисадмин должен фиксировать:
- схему сети;
- список серверов;
- адреса и роли;
- учётные записи и зоны ответственности;
- инструкции по типовым операциям;
- порядок аварийного восстановления;
- контакты поставщиков;
- календарь обслуживания.
Минимальный набор документов:
- инвентаризация активов;
- карта сети;
- список сервисов;
- план резервного копирования;
- инструкция по восстановлению;
- база типовых инцидентов;
- change log.
Автоматизация
Чем больше инфраструктура, тем меньше пользы от ручного труда. Настоящий сисадмин не только крутит вентили, но и строит автоматические клапаны.
Инструменты автоматизации:
- Bash;
- PowerShell;
- Ansible;
- Terraform;
- Python;
- cron / Task Scheduler;
- CI/CD для инфраструктурных задач.
Пример простого сценария на Bash:
#!/usr/bin/env bash
set -euo pipefail
LOGDIR="/var/log/app"
THRESHOLD=85
USED=$(df -h / | awk 'NR==2 {gsub("%","",$5); print $5}')
if [ "$USED" -ge "$THRESHOLD" ]; then
echo "Disk usage warning: ${USED}% on root filesystem" | mail -s "Disk alert" admin@company.local
fiАвтоматизация экономит время и снижает количество человеческих ошибок. А ошибки в системном администрировании обычно не хрустят тихо — они рвут магистраль.
Где заканчивается зона ответственности
Это важный момент: системный администратор не обязан быть всем на свете. В разных компаниях его путают с:
- сетевым инженером;
- DevOps-инженером;
- специалистом по ИБ;
- разработчиком;
- техподдержкой;
- “человеком, который знает ноутбуки”.
На деле границы должны быть прописаны:
- кто отвечает за рабочие станции;
- кто за серверы;
- кто за сеть;
- кто за безопасность;
- кто за приложения;
- кто принимает инциденты;
- кто утверждает изменения.
Если границы не определены, то админ превращается в универсальный редуктор: его крутят в любую сторону, пока не перегреется весь цех.
Как выглядит рабочий день системного администратора
Типичный день редко похож на “поставил сервер и ушёл”. Чаще это смесь плановых задач и внезапных тревог.
Утро:
- посмотреть мониторинг;
- проверить ночные бэкапы;
- изучить алёрты;
- убедиться, что критичные сервисы живы.
Днём:
- выдача доступов;
- установка обновлений;
- помощь пользователям;
- настройка новых рабочих мест;
- разбор тикетов;
- сопровождение изменений.
Вечером:
- обслуживание по окну;
- миграции;
- перезапуск сервисов;
- архивирование логов;
- проверка отчётов.
Мини-чеклист при инциденте
- Убедиться, что проблема воспроизводится.
- Определить масштаб: один пользователь, один сервер или весь сегмент.
- Проверить последние изменения.
- Посмотреть логи и метрики.
- Сравнить с известной нормой.
- Изолировать источник.
- Выполнить безопасный откат или обходной путь.
- Зафиксировать причину и последствия.
Какие навыки нужны системному администратору
Хороший админ — это не только человек, который помнит синтаксис команд. Это инженер, который умеет:
- разбираться в чужих системах;
- читать логи;
- мыслить причинно-следственно;
- общаться с пользователями без искр из-под клапанов;
- документировать;
- автоматизировать;
- принимать решения под давлением.
Базовый набор компетенций
- Linux и/или Windows Server;
- сеть на уровне TCP/IP, DNS, DHCP, VLAN, VPN;
- виртуализация;
- резервное копирование;
- мониторинг;
- скриптинг;
- основы ИБ;
- работа с тикетами и регламентами.
Что отличает сильного администратора
- он не гадает, а проверяет;
- он не лечит симптом, не понимая причину;
- он сначала делает безопасно, потом быстро;
- он всегда оставляет след в документации;
- он думает о восстановлении до того, как случилась авария.
Итог
Системное администрирование — это управление живой технической экосистемой. В ней всё взаимосвязано: пользователи, сети, серверы, доступы, бэкапы, безопасность, мониторинг и документация.
Если смотреть на дело без романтики, то системный администратор — это тот, кто не даёт цифровому заводу остановиться. Если посмотреть с другой стороны, то это старший механик огромной паровой машины, который держит давление в норме, не допускает утечек и знает, какой рычаг дёрнуть первым, когда в трубах начинает гудеть тревога.
⚙️ Машинное отделение ROADIT благодарит за прочтение.
Больше команд, шпаргалок и обзоров — на roadit.ru и в нашем Телеграф-канале.
📋 Все команды